|
I am a PhD student at PEARL Lab advised by Prof. Georgia Chalvatzaki from Oct 2024. My research interest lies in reinforcement learning, especially its applications (e.g., robotics, finance, and transportation) and high-performance and scalable systems. Prior to this, I was a visiting researcher at MIT CSAIL, advised by Prof. Pulkit Agrawal, where I conducted research on massively parallel simulation and sim-to-real in robotics. I received my bachelor's degree from Columbia University in May 2022, majoring in computer science. During my undergraduate studies, I was fortunate to work with Prof. Xiaodong Wang, Prof. Anwar Walid and Prof. Sharon (Xuan) Di.
|

|
|
|
|
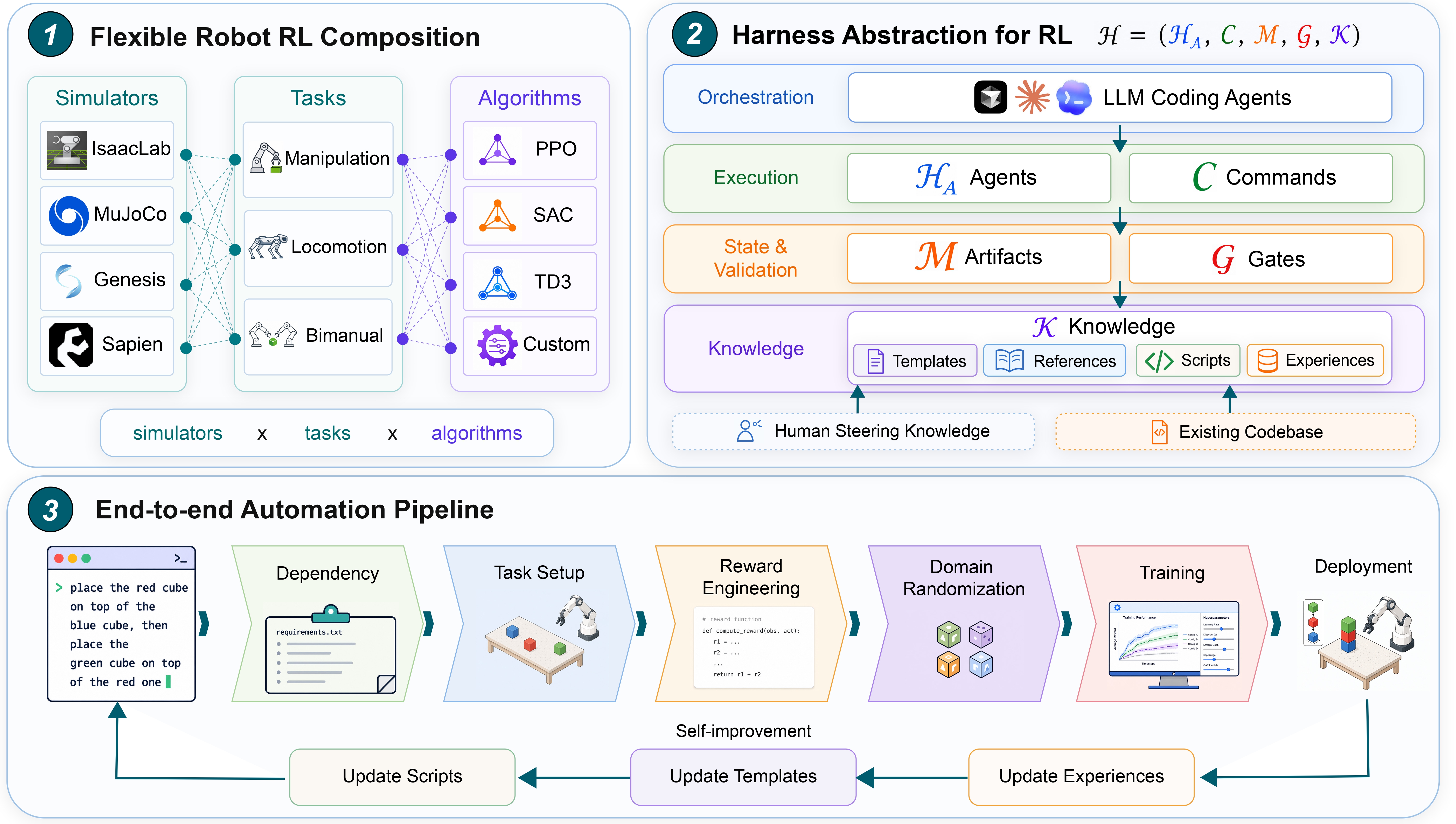
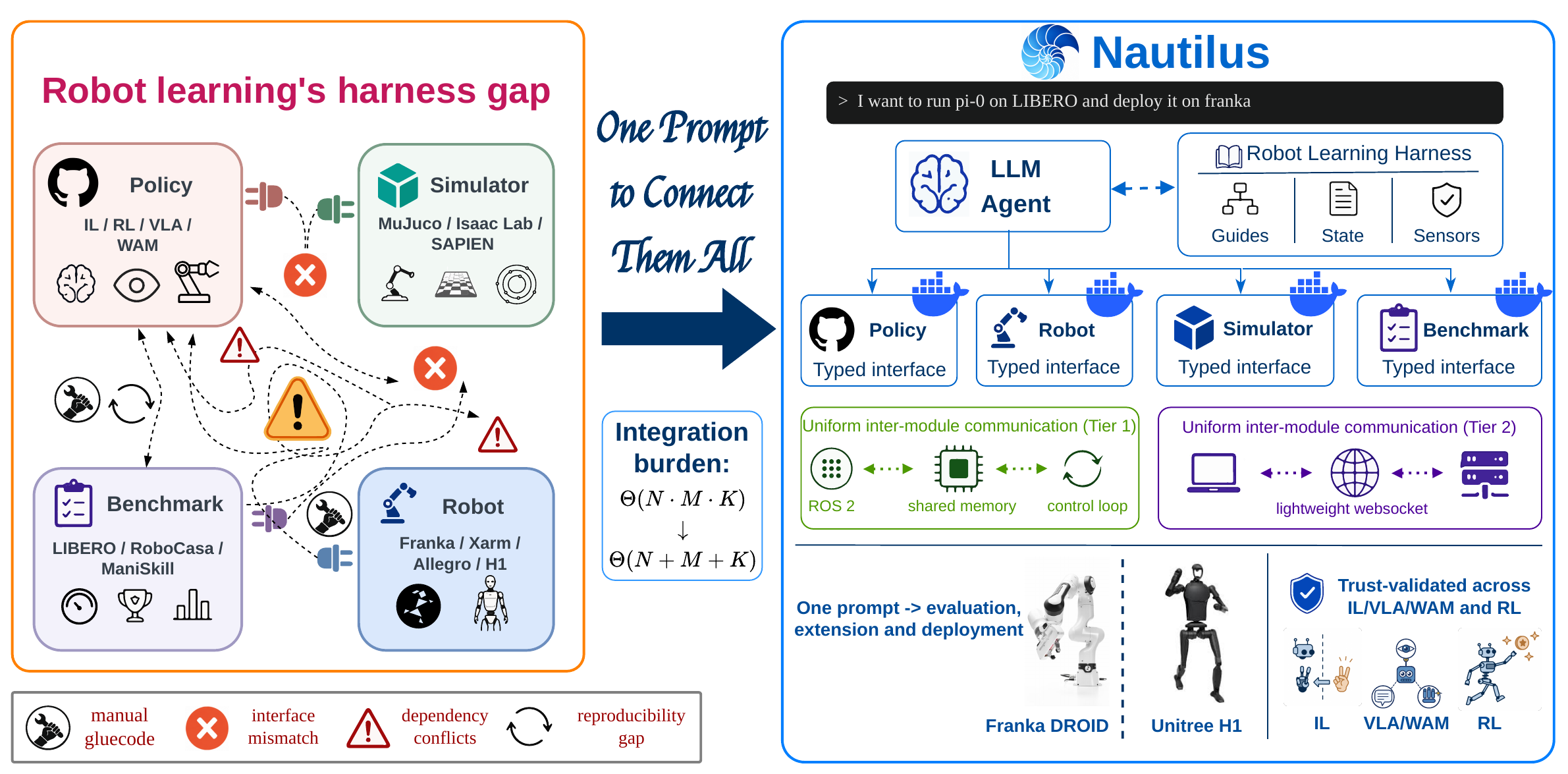
Zechu Li, Yufeng Jin, Xiao-Yang Liu, Puze Liu, Vignesh Prasad, Carlo D'Eramo, Georgia Chalvatzaki arXiv, 2026 paper / code An agentic framework that formulates the robot RL automation as a harness engineering problem and automates end-to-end simulation workflow from package installation to policy tuning. |
|
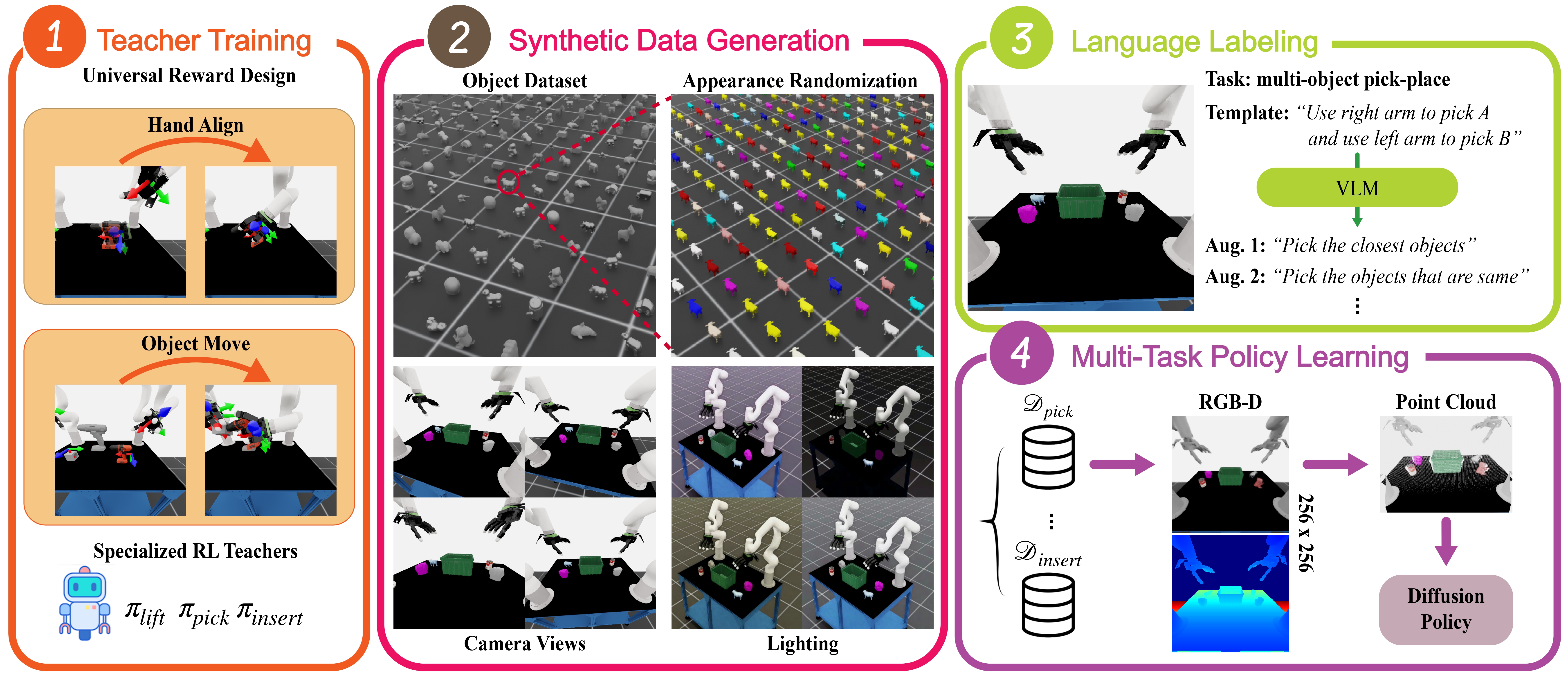
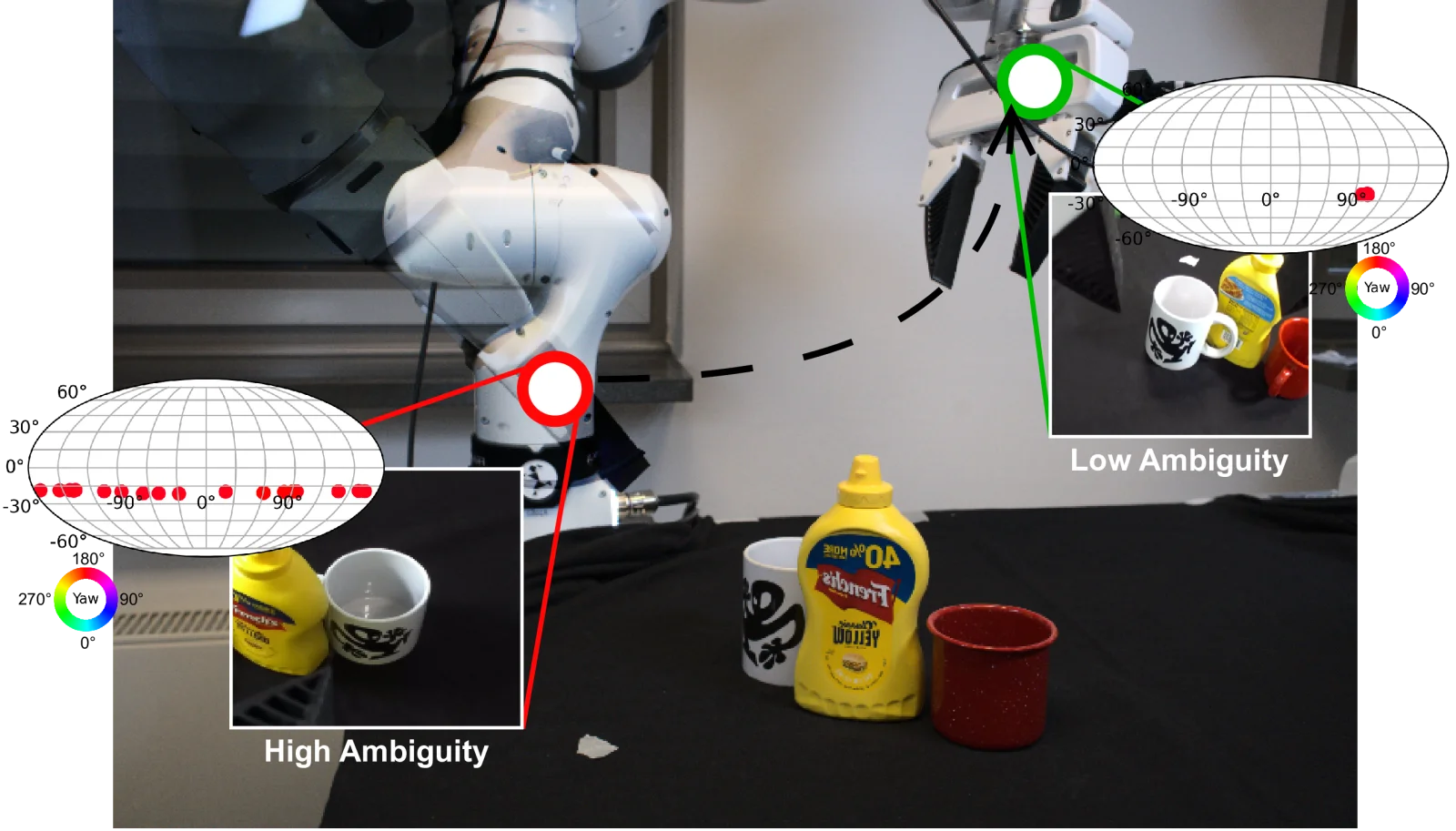
Zechu Li, Yufeng Jin, Puze Liu, Jan Peters, Georgia Chalvatzaki IROS, 2026 paper An RL-based data-generation pipeline for language-conditioned bimanual arm-hand manipulation. |
|
Zechu Li, Yufeng Jin, Daniel Ordoñez Apraez, Claudio Semini, Puze Liu, Georgia Chalvatzaki CoRL, 2025 paper / website / code A novel RL framework that explicitly leverages the inherent morphological symmetry in bimanual robotic systems to enable ambidextrous control. |
|
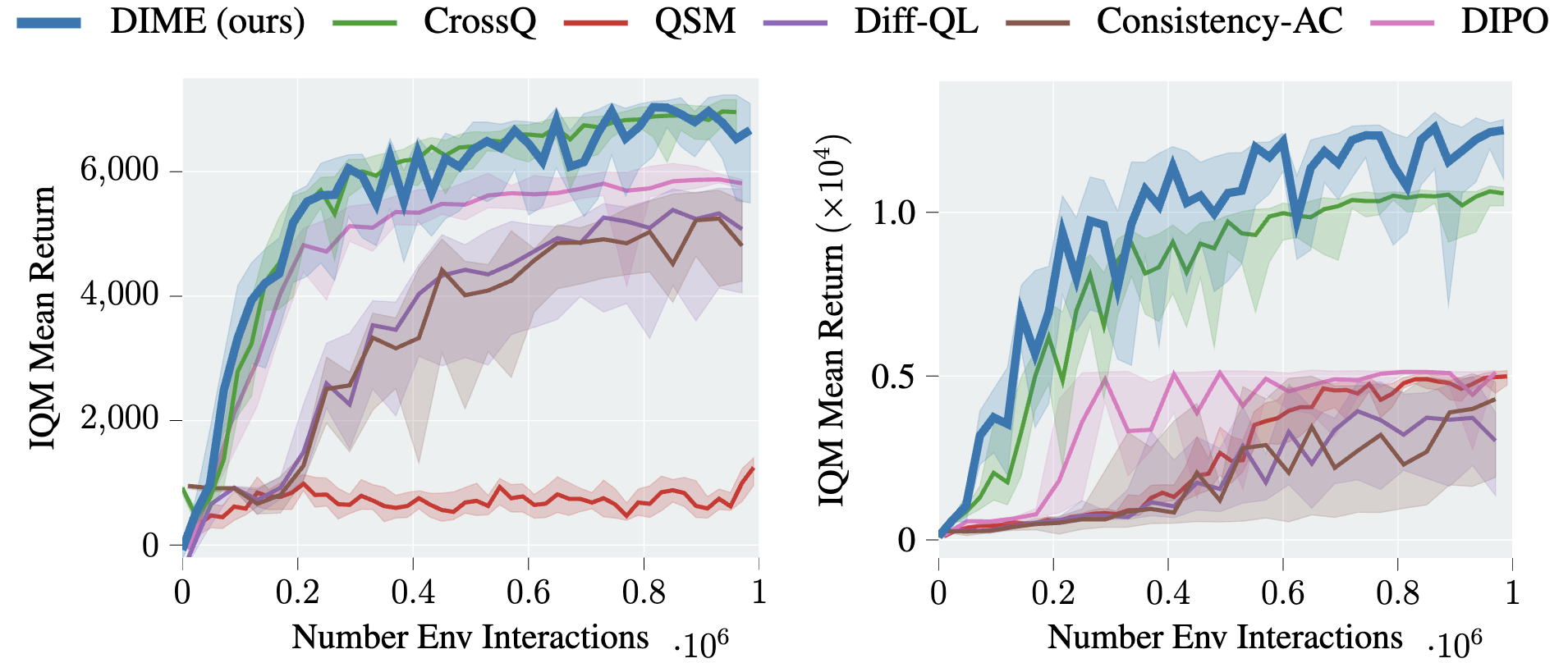
Onur Celik, Zechu Li, Denis Blessing, Ge Li, Daniel Palenicek, Jan Peters, Georgia Chalvatzaki, Gerhard Neumann ICML, 2025 paper / website / code A novel diffusion-based maximum entropy algorithm that achieves SOTA performance against both diffusion-based and non-diffusion methods. |
|
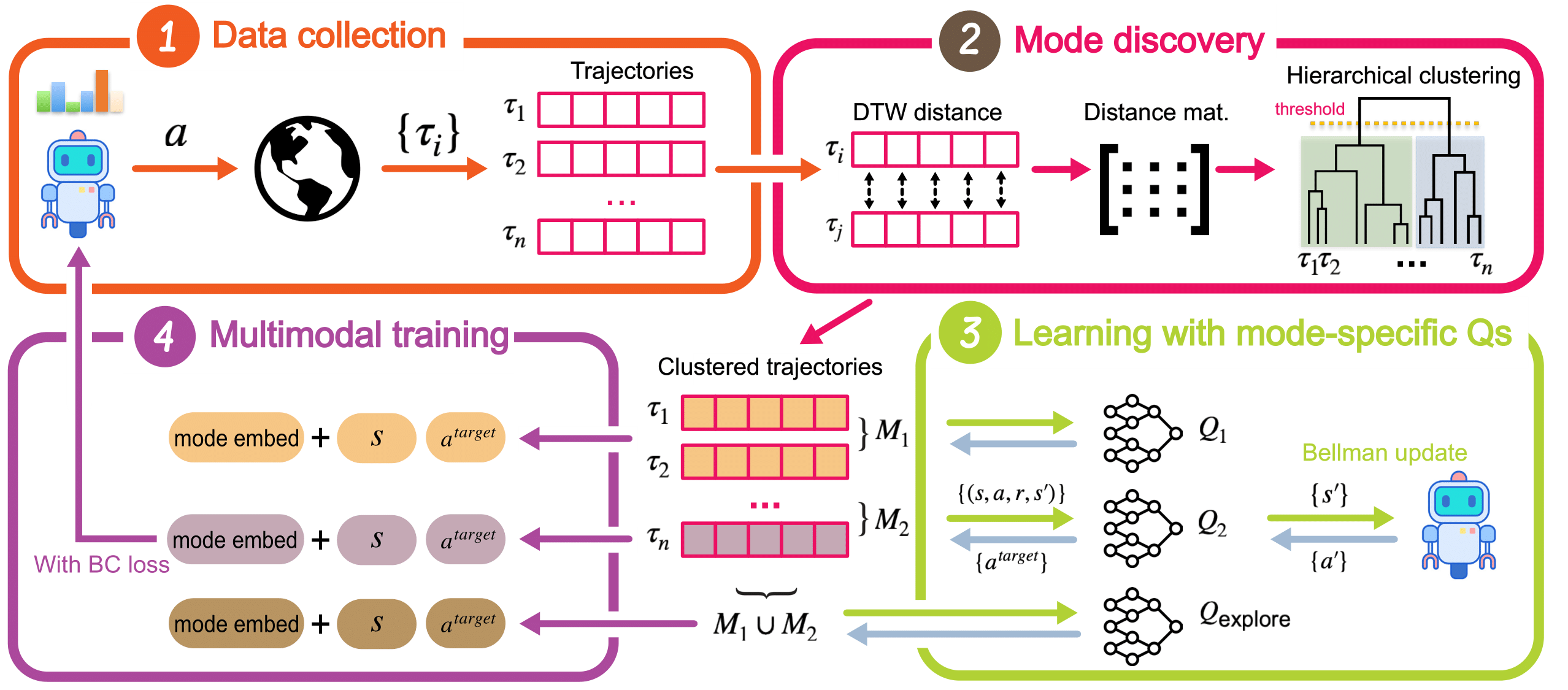
Zechu Li, Rickmer Krohn, Tao Chen, Anurag Ajay, Pulkit Agrawal, Georgia Chalvatzaki NeurIPS, 2024 paper / website / code A novel actor-critic algorithm that learns multimodal policies as diffusion models from scratch while maintaining versatile behaviors. |

|
Marcel Torne, Anthony Simeonov, Zechu Li, April Chan, Tao Chen, Abhishek Gupta*, Pulkit Agrawal* Robotics: Science and Systems (RSS), 2024 paper / website / code A system for robustifying real-world imitation learning policies via reinforcement learning in "digital twin" simulation environments constructed on the fly from small amounts of real-world data. |
|
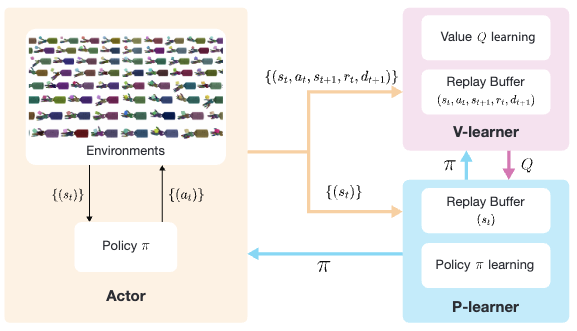
Zechu Li*, Tao Chen*, Zhang-Wei Hong, Anurag Ajay, Pulkit Agrawal ICML, 2023 paper / code A novel parallel Q-learning framework that scales off-policy learning to 10000+ parallel environments. |
|
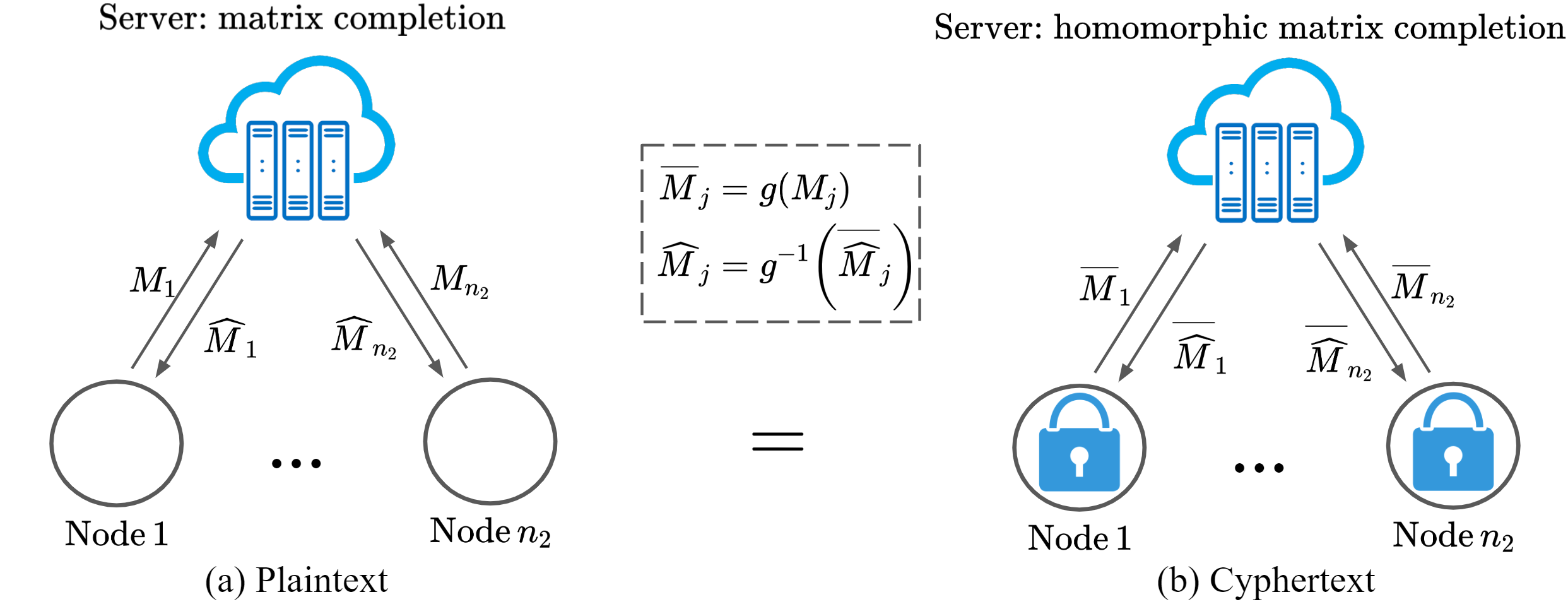
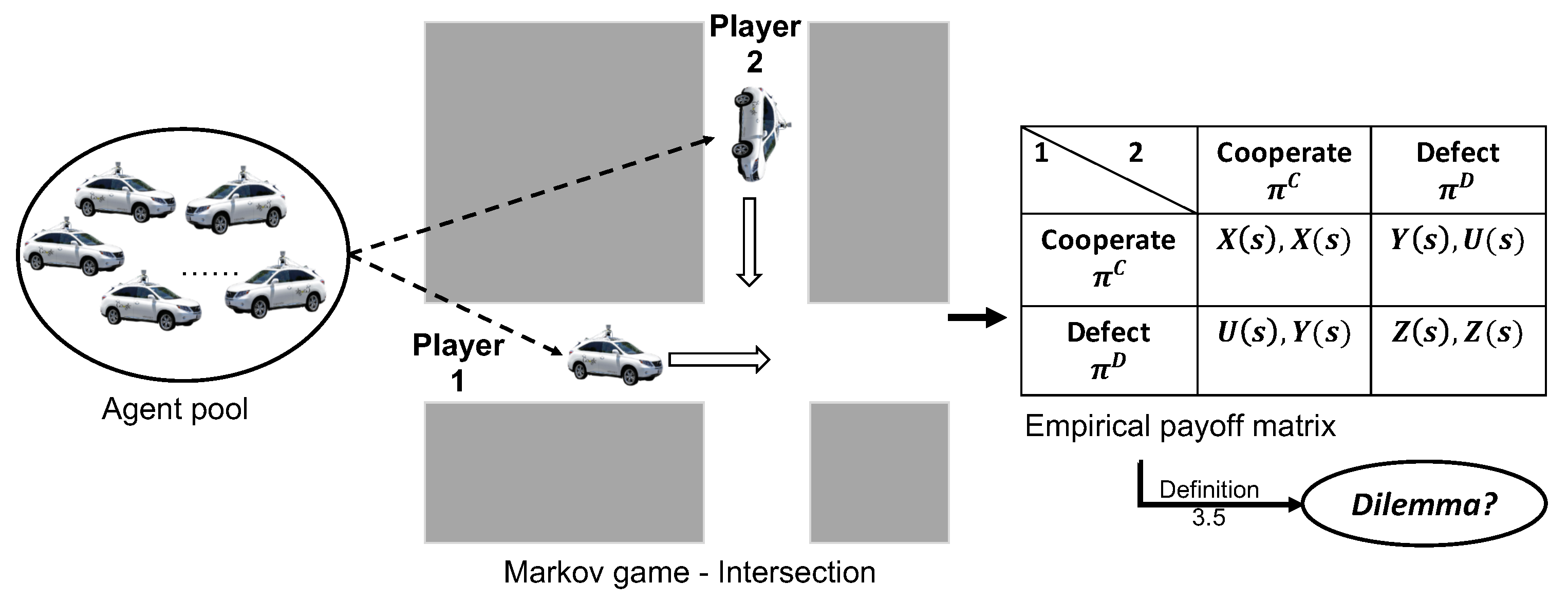
Xiao-Yang Liu*, Zechu Li*, Xiaodong Wang NeurIPS, 2022 paper A homomorphic matrix completion algorithm that satisfies the differential privacy property and reduces the best-known error bound to EXACT recovery at a price of more samples. |
|
|

|
|

|
project page / code / GitHub Star The first open-source framework to show the great potential of financial reinforcement learning. |

|
project page / code / GitHub Star
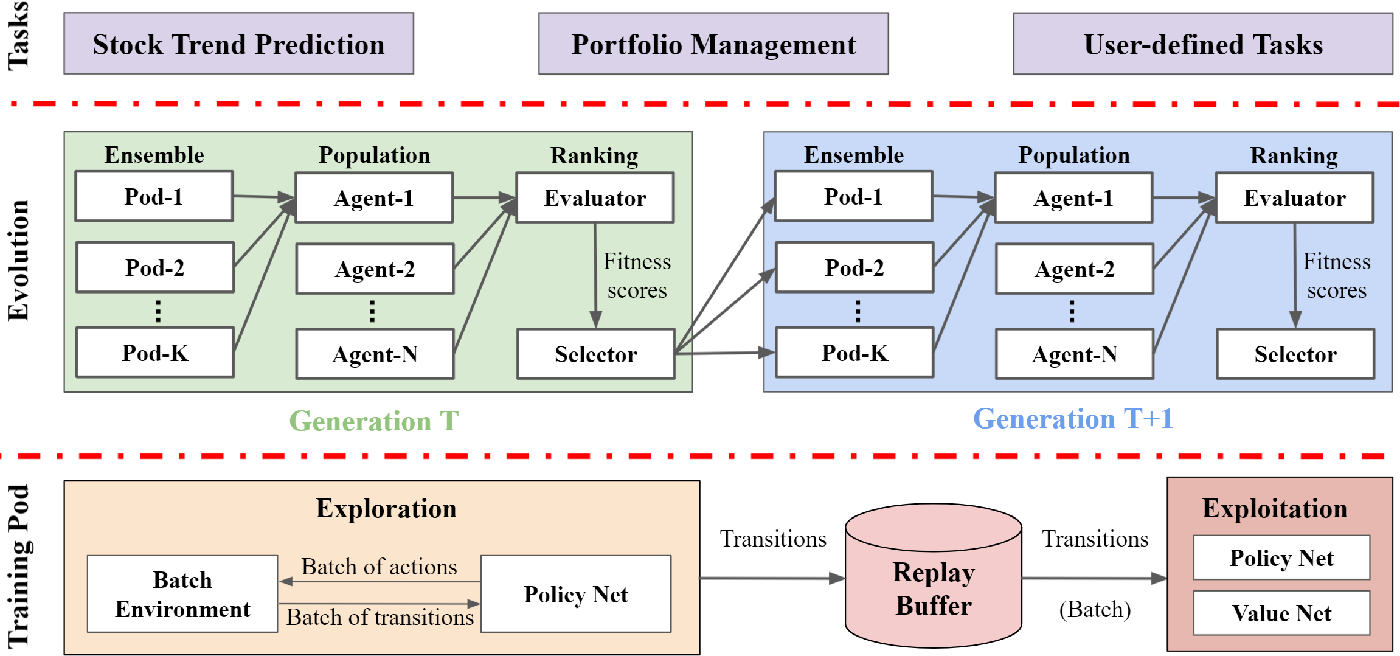
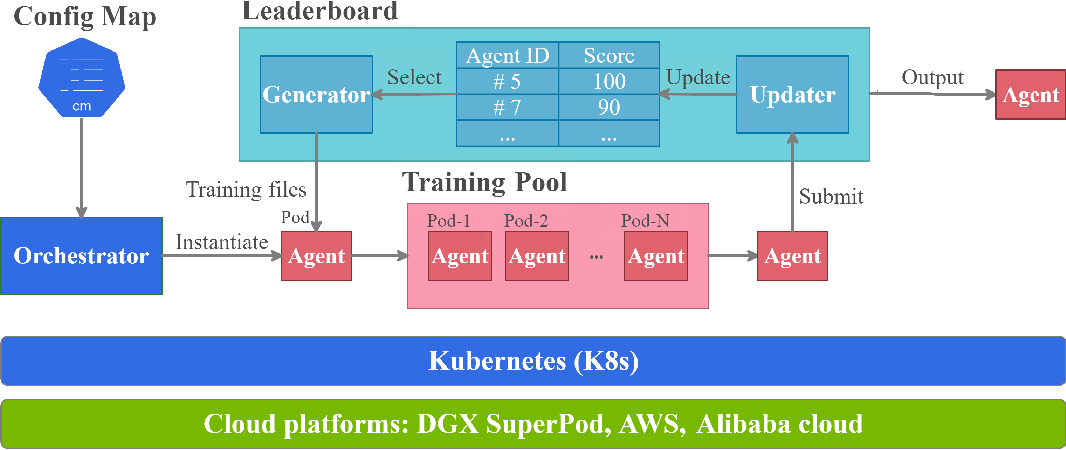
A massively parallel library for cloud-native deep reinforcement learning (DRL) applications.
|
|
|

|
Xiao-Yang Liu, Yiming Fang, Liuqing Yang, Zechu Li, Anwar Walid Tensors for Data Processing, Elsevier, 2021 chapter / book This chapter takes a practical approach to seek a better efficiency-accuracy trade-off, which utilizes high performance tensor decompositions to compress and accelerate neural networks by exploiting low-rank structures of the network weight matrix. |
|
|